1. 인코딩(Encoding)란?
코드화(문자의 번호를 컴퓨터에서 표현하는 방법), 암호화를 의미하며 반대말은 디코딩(decoding)이다. 어떤 정보를 정해진 규칙에 따라 변환하는 것(en-code-ing)을 일컫는다.
2. 유니코드(Unicode)란?
유니코드는 전 세계의 모든 문자를 담아 세계공통 코드 집합을 만들어 모두가 이 집합으로 인해 언어를 구현하자는 의도로 만들어졌다. 간단히 말해, 유니코드(unicode)는 모든 문자에 index를 부여하는 것이다.
( index 참고: http://www.unicode.org/charts/)

※ 한글과 같이 모음, 자음, 초성, 중성의 조합으로 여러가지 글자를 표현할 수 있는 언어는 index로 모두 줄 수 없다. 그래서 유니코드는 완전한 글자를 제공해 주기도 하지만, 글자를 조립할 수 있도록 조립가능한 글자를 제공해준다.( Hangul Jamo - Korean combining alphabet - http://www.unicode.org/charts/PDF/U1100.pdf )
index를 표시하는 방법에는 UTF(Unicode Transformation Format)와 UCS(Universal Character Set) 두가지 종류가 있다.
유니버설 문자 집합(Universal Character Set, UCS)은 ISO 10646이라는 국제 표준이고, 유니코드도 국제 표준 문자 집합니다. 둘 다 십만 개 이상의 문자를 담고 있으며, 각 문자마다 고유 이름과 코드 포인트가 정해져 있다. 두 표준 모두 인코딩 방식으로 따로 정해두고 있다.
유니코드는 한 문자를 1~4개의 8비트로 인코딩하는 UTF- 8방식, 한 문자를 1~2개의 16비트로 인코딩하는 UTF- 16방식, 유니코드 문자를 정확히 32비트로 인코딩하는 UTF - 32 방식이 있다.
전 세계 사용자를 위해 어플리케이션을 현지화하는 방법과 정규표현식을 이용한 막강한 매칭 구현 방법을 알아보자.
C나 C++프로그래밍을 배울 때 각각의 문자를 아스키(ASCII) 코드를 표현하는 바이트로 취급했다. 아스키 코드는 7비트로 구성됐으며 주로 8비트 char 타입으로 표현한다.
현지화에서 가장 중요한 원칙 중 하나는 소스 코드에 특정 언어로 된 스트링을 절대로 넣으면 안된다는 것이다. 마이크로소프트 윈도우 애플리케이션을 개발하는 환경에서는 현지화에 관련된 스트링을 STRINGTABLE이란 리소스로 따로 빼둔다.
함수: Format( ) 스트링 리소스를 불러오면서 $1에 해당하는 부분을 n이란 값으로 대체한다.
1. 와이드 문자
모든 언어가 한 문자를 1바이트, 즉 8비트에 담을 수 있는 것은 아니다. c++는 wchar_t라는 와이드 문자(확장 문자) 타입을 기본으로 제공한다. 한국어나 아랍어처럼 아스키 문자를 사용하지 않는 언어는 c++에서 wchar_t타입을 표현하면 된다.하지만 c++표준은 wchar_t의 크기를 명확히 정의하지 않고 있다. 어떤 컴파일러는 16비트 반면 다른 컴파일러는 32비트로 처리하기도 한다. 그래서 크로스 플랙폼을 지원하도록 코드를 작성하려면 wchar_t의 크기가 일정하다고 가정하면 위험하다. (c++에서 제공하는 char16_t , char32_t를 이용하면 문제에 대처하는 데 도움 된다.)
스트링이나 문자 리터널을 wchar_t타입으로 지정하려면 리터널 앞에 L을 붙이면 된다. 그러면 와이드 문자 인코딩을 적용한다. 흔히 사용하는 타입이나 클래스마다 와이드 문자 버전이 존재한다.
wchar_t wStringMsg = L'm';
(string - wstring)
입출력 와이드 문자 버전 :
(cout - wcout), (cin - wcin), (cerr - wcerr), (clog - wclog)
(ofstream - wofstream), (ifstream - wifstream)
using u16string = basic_string<char16_t>
using u32string = basic_string<char32_t>
※ c++에서 제공하는 스트링 접두어
- u8 : UTF-8 인코딩을 적용한 char 스트링
- u : char16_t 스트링 리터널을 표현하며, 컴파일러에 __STDC_UTF_16__이 정의돼 있으면 UTF-16을 적용한다.
- U: char32_t 스트링 리터널을 표현하며, 컴파일러에 __STDC_UTF_32__가 정의돼 있으면 UTF-32를 적용한다.
- L: wchar_t 스트링 리터널을 표현하며, 인코딩 방식은 컴파일러마다 다르다.
2. 변환
C++표준에서는 다양한 방식으로 인코딩된 문자를 쉽게 변환하도록 codecvt라는 클래스 템플릿을 제공한다.
<locale>헤더 파일을 보면 네 가지 인코딩 변환 클래스가 정의 돼 있다.
| codecvt<char, char, mbstate_t> | 항등 변환, 즉 같은 것끼리 변환해서 실질적으로 변환이 이뤄지지 않느낟. |
| codecvt<char16_t, char, mbstate_t> | UTF-16과 UTF-8을 변환한다. |
| codecvt<char32_t, char, mbstate_t> | UTF-32과 UTF-8을 변환한다. |
| codecvt<wchar_t, char, mbstate_t> | 와이드 문자와 내로우 문자 인코딩을 변환한다. |
C++17부터 <codecvt>라는 헤더 파일 전체와 두가지 변환 인터페이스가 폐기됐다. C++표준 위원회는 이러한 것들이 에러 처리에 불리하다는 이유로 폐기하도록 결정했다. C++표준 위원회에서 보자 적합하고 안전한 대안을 마련할 때까지는 ICU와 같은 서드파티 라이브러리를 사용하자.
3. 로케일 <locale>과 패싯
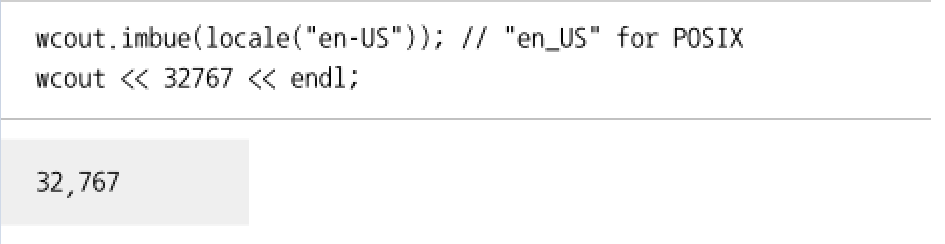
문자 집합은 나라마다 데이터 표현하는 방식이 다른 여러 가지 요소 중 하나에 불과하다. 문자가 비슷한 나라마저도 날짜나 화폐를 표현하는 방식이 다르다. 이렇게 특정한 데이터를 문화적 배경에 따라 그룹으로 묶는 방식을 C++에서는 로케일이라고 부른다. 로케일은 날짜 포맷, 시간 포맷, 숫자 포맷 등으로 구성되는데 이러한 요소를 패싯이라고 부른다. I/O스트림을 사용할 때는 데이터의 포맷을 특정한 로케일에 맞춘다.

문자 분류
<locale> 헤더 파일의 std::isspace( ), isblank( ), iscntrl( ), isupper( ), islower( ), isalpha( ), isdigit( ), ispunct( ), isxdigit( ), isalnum( ), isprint( ), isgraph( ) 둥과 같은 문자 분류 함수가 정의돼 있다. 이들 함수는 두 개의 매개변수를 받는다.
bool result = isupper('A', locale(""));
패싯
특정한 로케일에서 패싯을 구하려면 std::use_facet( ) 함수를 호출해야 한다. 이때 use_facet( )의 인수로 locale을 지정한다. 아래는 c++표준에서 정한 패싯의 범주이다.

미국식 영어와 영국식 영어에 대한 로케일과 패싯으로 두 나라의 화폐 기호를 출력하는 예제이다.


Reference.
- [문자인코딩] 유니코드, UTF-8, UTF-16, UTF-32 간단 정리. (ggaman.com)
- (도서) 출처: 전문가를 위한 c++ (개정4판)
'👨🏻💻 programming > ◽ C, C++, C#' 카테고리의 다른 글
| [C++] Map의 Key로 Class/Struct 넣기 (2) | 2023.08.11 |
|---|---|
| (C#) 닷넷(.NET)?, 윈도우 폼(Windows Forms)? (0) | 2022.09.16 |
| (c++) 디자인 패턴 01(싱글톤, 추상 팩토리, 옵저버, 프록시, 어댑터) (2) | 2022.08.24 |
| (c++17) decltype, 로 스트링 리터럴, static, const, extern, mutable, constexpr, 타입 앨리어스, 스코프, 레퍼런스, 어트리튜트 (4) | 2022.08.11 |
| (c++17) 전처리 지시자, if-switch 이니셜라이저, __func__, 구조적 바인드 (0) | 2022.08.04 |

존잘 프로그래머가 되고싶어
![[C++] Map의 Key로 Class/Struct 넣기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbygJls%2FbtsOe5sgQDv%2FAAAAAAAAAAAAAAAAAAAAAKe3l0vKPiBAedQ_3gHONG2x_EYWY0Lmt3j8VTzI__6P%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DL5D70UYVWc%252BBbIx6qp4OlJM%252Fw7g%253D)


